工業大數據解決方案檢視原始碼討論檢視歷史
 |
工業大數據解決方案東軟工業大數據解決方案是利用成熟的東軟自主研發的技術平台,結合分析建模工 具,不斷挖掘數據價值,改變企業生產服務模式,降低資源損耗,減少運營成本,提高 生產質量,增加產出效益,驅動設計創新,為製造企業創造價值。
一、解決方案簡述
1、 方案簡介與功能目標
東軟工業大數據[1]解決方案是利用成熟的東軟自主研發的技術平台,結合分析建模工 具,不斷挖掘數據價值,改變企業生產服務模式,降低資源損耗,減少運營成本,提高 生產質量,增加產出效益,驅動設計創新,為製造企業創造價值。
2、 技術體系與技術特點
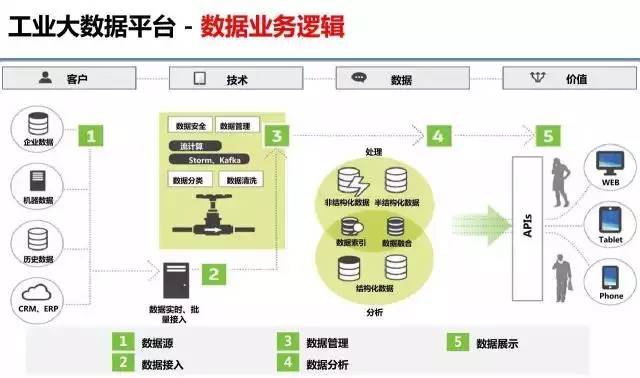
(1)總體架構
工業大數據解決方案共劃分為數據採集層、數據傳輸層、雲基礎設施層、雲數據資 源層、雲數據分析層、雲環境支撐層及服務應用層等七個層面。總體架構如下圖所示:
工業大數據解決方案共劃分為數據採集層、數據傳輸層、雲基礎設施層、雲數據資 源層、數據採集層包含直接從設備採集數據,從DNC等控制系統採集數據以及與MES等 信息系統採集來的數據;數據傳輸層的主要功能是把信息感知層採集到的數據,通過雲 平台的標準接口傳輸至雲計算資源層。雲基礎設施層:是支持基礎數據資源庫、大數據服務支撐平台以及面向各領域應用及服務運行的基礎環境設施,主要包括網絡、主機、存儲、安全等網絡及硬件基礎環境,同時部署數據庫[2]、中間件和ESB總線等系統軟件; 雲數據資源層:分為數據採集子層和基礎數據資源庫子層。數據採集子層數據的收集和 前處理,去除冗餘,分類並建立統一索引。基礎數據資源庫子層完成分類數據的存儲和 處理;基於相關業務標準和成熟的各領域業務模型,建立的專業領域數據庫,實現數據 的統一管理。數據資源層通過數據加載、數據清洗、數據轉換及數據壓縮將基礎數據統 一為標準化數據表現形式,加載和保存到各領域數據庫中,供上層數據分析層使用;雲數據分析層:以大數據科學分析平台為核心,提供分布式機器學習能力,開放數據挖掘 能力,為工業互聯網應用平台構築通用數據挖掘能力,支持製造企業以及產業協作的生 產管理、分析決策的科學化、智能化、精細化服務功能實現,提供經濟運行、科技創新、 綠色發展、集群發展、對外交流等大數據監測、分析、預測和預警等基本理論分析方法 和工具;雲環境支撐層:主要面向製造企業以及產業協作等不同的服務走向和用戶,屏 蔽底層工業大數據採集、存儲、分析以及決策的具體細節,以統一的定製化服務模式和 應用功能接口,通過雲計算應用模式展現給服務對象。高級分析服務層主要提供設備健 康檢測、產品質量檢測、工藝流程優化、高級生產計劃、能源環保監測等服務。
(2) 技術架構體系
依託東軟自主的RealSightloT產品,構建工業大數據基礎平台。共包含數據接入層、 數據存儲層、數據分析層、用戶訪問層、管理控制層等四個層面。數據接入層,負責與 外部數據源進行直接的交互通過,通過多種數據接口來滿足不同的數據接入要求;數據 存儲層,負責平台數據的持久化以及數據運行態的數據訪問,提供整個平台的數據基礎, 對分布式、內存型、關係型等數據,分別進行組織管理;數據分析層,在平台內實現數 據供應內核,在數據供內核基礎上,實現多種業務模型,提供系統業務能力;用戶訪問 層,提供HTML/Dataviz提供圖形化顯示能力,以及多種圖表展示能力;管理控制層, 負責提供整個平台體系的權限、安全、調度控制。
(3) 技術路線
結合工業大數據在工業企業和行業應用的現狀,以及東軟雲計算、大數據平台產品 的相關積累,本項目將遵循的產品工藝及技術路線說明如下:
1)採用J2EE作為應用系統架構:應用系統架構將採用J2EE架構進行設計,支持
N—tier服務模式,使系統具有很好框架和靈活性;
2) 採用多層服務模式,表現層與業務處理層和數據通訊層分隔,在增加一個新的訪問渠道時,僅增加渠道驅動,改變內容展示格式,而事務處理和與後台的數據通訊及 處理不作任何修改;
3) 採用不同技術實現各類工業數據接入:在與應用系統接入解決方案中,平台應 能提供多種技術實現方式供應用系統選擇,如Web Service (Java> .NET實現)、C#的 DLL、C的DLL,以滿足各類系統的接入,以保證平台可用性和可推廣性。支持異構系 統,至少包括Oracle、DB2、MS SQL Server,以及基於J2EE和.NET架構的應用;數據 傳輸應支持各類主要的消息協議(http, jms, socket, ftp, smtp, file, soap);支持同步 和異步傳輸以及斷點續傳,保證的數據傳輸的完整性和安全性;
4) 遵循XML數據交換標準:可擴展標記語言(XML)是Web上的數據通用語言。 XML是一種開放的標準,XML語言不受任何實體的控制也不歸任何實體所有。XML 可以擴展,XML標籤可以被任何人創建並被其他人所採用。它使開發人員能夠將結構 化數據,從許多不同的應用程序傳遞到桌面,進行本地計算和演示。XML允許為特定 應用程序創建唯一的數據格式。它還是在服務器之間傳輸結構化數據的理想格式;
5) 採用關係型數據庫與Nosql相結合的方式實現數據存儲:NoSQL是一種與關係 型數據庫管理系統截然不同的數據庫管理系統,它的數據存儲格式可以是鬆散的、通常 不支持Join操作並且易於橫向擴展。也可以稱之為非關係型數據庫;
6) 採用面向服務(SOA)的架構作為應用服務框架:本項目總體應用框架將採用 SOA (Service-Oriented Architecture,面向服務架構)架構,利用基於SOA的系統構建 方法,一個基於SOA架構的系統中的所有的程序功能都被封裝在一些功能模塊中,利 用這些已經封裝好的功能模塊組裝構建我們所需要的程序或者系統,而這些功能模塊就 是SOA架構中的不同的服務(services);
7) 採用分布式Hadoop作為計算框架:Hadoop是一個分布式計算系統基礎架構。 用戶可以在不了解分布式底層細節的情況下,開發分布式程序,充分利用集群的威力進 行高速運算和存儲。Hadoop是一個能夠讓用戶輕鬆架構和使用的分布式計算平台。它 主要有以下幾個優點:高可靠性、高擴展性、高效性、高容錯性;
8) 採用分布式內存計算技術Spark作為數據科學計算框架:Spark是UC Berkeley AMP lab所開源的類Hadoop MapReduce的通用並行框架,Spark,擁有Hadoop MapReduce所具有的優點;但不同於MapReduce的是Job中間輸出結果可以保存在內 存中,從而不再需要讀寫HDFS,因此Spark能更好地適用於數據挖掘與機器學習等需 要迭代的MapReduce的算法。Spark啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載;
9) 採用分布式流數據處理框架storm實時數據預處理。Storm為分布式實時計算提 供了一組通用原語,可被用於「流處理」之中,實時處理消息並更新數據庫。這是管理 隊列及工作者集群的另一種方式oStorm也可被用於「連續計算"(continuous computation), 對數據流做連續查詢,在計算時就將結果以流的形式輸出給用戶。
10) 採用W3C Schema 1.0規範的XML元數據描述;
採用 W3C Web Services Description Language (WSDL) v2.0規範的 Web服務描述;
11) 採用 W3C JavaScript Object Notation for Linked Data (JSON-LD) 1.0 規範的傳 輸互聯數據描述。
(4)技術創新及技術難點
1) 面向工業大數據應用建模的超參數搜索
超參數的選擇直接影響着支持數據挖掘算法的泛化性能和回歸效驗,是確保數據挖 掘算法優秀性能的關鍵。針對超參數窮舉搜索方法的難點,提出了正交設計超參選擇方 法,並分析了基於混合核函數(比單一核函數具有更好的收斂性和模型適應性)各個超 參數的取值範圍,選定了每個參數的試驗水平。通過考慮參數間的正交性和交互性,選取最優超參數組合下的算法模型。
2) 基於實時流式計算框架的動態業務拓撲更新
工業生產的業務和產業協調發展業務都存在也不確定性,隨時可能發生業務流程或 業務方向的變化,因此,面臨着己經上線運行的數據挖掘模型可能需要調整和更新,以 適用於當前的工業生產和產業協調發展的業務需求。對於每個算法邏輯來說,更新是不 可避免的,如何在不停止服務的情況下進行更新是必要的。由於實現了架構與算法的剝 離,因此算法可以以一個單獨的個體進行更新。
3) 自動化算法選擇和模型訓練
工業大數據平台要提供大量的數據挖掘模型來支持工業生產的業務和產業協調發 展業務的預測和預警等。比如,當構建某個業務目標預測性的數據挖掘模型時,有多個 算法適用於該場景,如果由數據科學家或數據分析師逐個應用不同算法來訓練模型,對 比每個模型的評估結果,最終選擇最優模型。這種方式耗時耗力。不能快速獲取最優數 學模型。採用自動化模型訓練,基於相同特徵變量,自動選擇不同算法進行模型訓練。
4) 多模型交叉評估和驗證
目前常見的數據挖掘工具,只能使用歷史數據集,提供離線評估功能,不能適用於 不斷在生產大量實時數據的工業大數據分析挖掘場景。多模型交叉評估和驗證,在模型 效果評估方面,提供了兩大類評估方法,包括線上A/B測試以及離線評估,離線評估中 包含了多項評估指標,例如準確度、召回率、Ranking、相關度等。線上評估實現多種 高效A/B分流分組策略,能夠在不影響效率的前提下更加準確的發現模型的有效性。
5) 面向工業製造生產設備的預測性維護技術
製造企業都有大量的生產設備在運行,通常設備的維護方式是採用傳統的事後維修 或預防性維護,造成設備停產或不必要的停機保養,浪費大量的資源。目前常用的生產 設備檢測和分析的方法是振動信號分析與處理方法,以快速傅立葉變換(FFT)為基礎, 採用多種有效的震動信號處理方法(如快速卷積、相關、自譜、互譜、倒譜、細化譜及 傳遞分析等)在機械故障診斷技術應用中起到了非常大的作用。然而這類基於平穩過程 的經典信號處理方法,僅從時域或頻域給出信號統計的平均結果,無法同時兼顧信號在 時域和頻域中的全貌和局部。
6) 應用於製造工藝流程優化混合模型
採用DMAIC、標杆瞄準(bench-marking)和ESIA分析模型,針對影響製造工藝 流程質量的多種因素,運用統計方法可找出影響製造工藝流程的主要原因。改進是確定 影響y (輸出)的主要原因x(輸入),尋求x與y的關係,建立x的允許變動範圍。結 果與原因呈現出一個類似函數的模型,艮"y=f (xl, x2,……xp) +e o改進是實現目 標的關鍵步驟。相關分析、回歸分析、試驗設計、方差分析等都是改進步驟中的統計工 具。當用統計方法找到了要改進的環節和方案之後,重要的是去實施它。通過正確跟蹤 數據,建立起回歸模型,用回歸模型進行預測和控制,使公司收益和顧客滿意度達到最大。
參考文獻
- ↑ 大數據有什麼作用? ,搜狐,2023-04-24
- ↑ 史上最全分布式數據庫概述,搜狐,2019-06-12