聚簇索引檢視原始碼討論檢視歷史
 |
聚簇索引也叫簇類索引,是一種對磁盤上實際數據重新組織以按指定的一個或多個列的值排序。由於聚簇索引的索引頁面指針指向數據頁面,所以使用聚簇索引查找數據幾乎總是比使用非聚簇索引快。每張表只能建一個聚簇索引,並且建聚簇索引需要至少相當該表120%的附加空間,以存放該表的副本和索引中間頁。
簡介
聚簇索引(Clustered Index)並不是一種單獨的索引類型,而是一種數據存儲方式。當表有了聚簇索引的時候,表的數據行都存放在索引樹的葉子頁中。
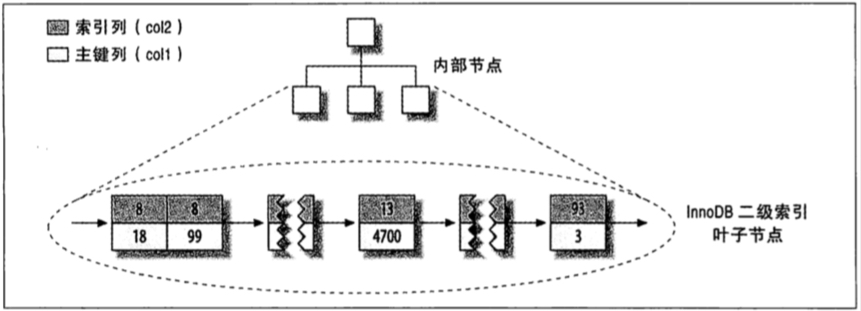
非聚簇索引(NoClustered Index),又叫二級索引。二級索引的葉子節點中保存的不是指向行的物理指針,而是行的主鍵值。
二、應用不同:
在《數據庫原理》裡面,對聚簇索引的解釋是:聚簇索引的順序就是數據的物理存儲順序,而對非聚簇索引的解釋是:索引順序與數據物理排列順序無關。正式因為如此,所以一個表最多只能有一個聚簇索引。
在SQL Server中,索引是通過二叉樹的數據結構來描述的,我們可以這麼理解聚簇索引:索引的葉節點就是數據節點。而非聚簇索引的葉節點仍然是索引節點,只不過有一個指針指向對應的數據塊。
特點介紹
聚簇索引也稱為聚集索引,聚類索引,簇集索引,聚簇索引確定表中數據的物理順序。聚簇索引類似於電話簿,後者按姓氏排列數據。由於聚簇索引規定數據在表中的物理存儲順序,因此一個表只能包含一個聚簇索引。但該索引可以包含多個列(組合索引),就像電話簿按姓氏和名字進行組織一樣。漢語字典也是聚簇索引的典型應用,在漢語字典里,索引項是字母+聲調,字典正文也是按照先字母再聲調的順序排列。
聚簇索引對於那些經常要搜索範圍值的列特別有效。使用聚簇索引找到包含第一個值的行後,便可以確保包含後續索引值的行在物理相鄰。例如,如果應用程序執行的一個查詢經常檢索某一日期範圍內的記錄,則使用聚集索引可以迅速找到包含開始日期的行,然後檢索表中所有相鄰的行,直到到達結束日期。這樣有助於提高此類查詢的性能。同樣,如果對從表中檢索的數據進行排序時經常要用到某一列,則可以將該表在該列上聚簇(物理排序),避免每次查詢該列時都進行排序,從而節省成本。
思想
1、大多數表都應該有聚簇索引或使用分區來降低對表尾頁的競爭,在一個高事務的環境中,對最後一頁的封鎖嚴重影響系統的吞吐量。
2、在聚簇索引下,數據在物理上按順序排在數據頁上,重複值也排在一起,因而在那些包含範圍檢查(between、<、<=、>、>=)或使用group by或orderby的查詢時,一旦找到具有範圍中第一個鍵值的行,具有後續索引值的行保證物理上毗連在一起而不必進一步搜索,避免了大範圍掃描,可以大大提高查詢速度。
3、在一個頻繁發生插入操作的表上建立聚簇索引時,不要建在具有單調上升值的列(如IDENTITY)上,否則會經常引起封鎖衝突。
4、在聚簇索引中不要包含經常修改的列,因為碼值修改後,數據行必須移動到新的位置。
5、選擇聚簇索引應基於where子句和連接操作的類型。
候選列
2、按範圍存取的列,如pri_order>100 and pri_order<200。
3、在group by或order by中使用的列。
4、不經常修改的列。
5、在連接操作中使用的列。
聚簇索引表
聚簇是指:如果一組表有一些共同的列,則將這樣一組表存儲在相同的數據庫塊中;聚簇還表示把相關的數據存儲在同一個塊上。利用聚簇,一個塊可能包含多個表的數據。概念上就是如果兩個或多個表經常做鏈接操作,那麼可以把需要的數據預先存儲在一起。聚簇還可以用於單個表,可以按某個列將數據分組存儲。
更加簡單的說,比如說,EMP表和DEPT表,這兩個表存儲在不同的segment中,甚至有可能存儲在不同的TABLESPACE中,因此,他們的數據一定不會在同一個BLOCK里。而我們又會經常對這兩個表做關聯查詢,比如說:select * from emp,dept where emp.deptno = dept.deptno .仔細想想,查詢主要是對BLOCK的操作,查詢的BLOCK越多,系統IO就消耗越大。如果我把這兩個表的數據聚集在少量的BLOCK里,查詢效率一定會提高不少。
比如我將值deptno=10的所有員工抽取出來,並且把對應的部門信息也存儲在這個BLOCK里(如果存不下了,可以為原來的塊串聯另外的塊)。這就是索引聚簇表的工作原理。 [1]
視頻
聚簇索引就是主鍵索引嗎?